搜索引擎的运行原理也是SEO新手入门需要了解的知识,能够帮助你对搜索引擎这个工具有个整体的认知。对于所有的搜索引擎来说,他们基本的工作流程都是相同的。
- 首先是抓取,搜索引擎通过蜘蛛(搜索引擎的抓取程序),抓取互联网上的众多网站信息;
- 然后是收录,搜索引擎会把抓取到的网页信息,收录到自己的数据库中;
- 最后是排名,搜索引擎根据用户使用的搜索词通过它的特定算法在数据库中找到匹配的相关页面,通过搜索结果的形式展示给用户。
抓取规则(Crawling)
搜索引擎会利用蜘蛛工具抓取互联网上可以抓取到的所有网页信息。可能有人会问蜘蛛工具是什么?互联网上的网站是相互链接的,网站内部的叫做内链,对外的链接叫做外链。这些链接就像一张大网一样,把几乎所有的网站都连接到了一起,从而组合成了整个互联网。
而搜索引擎的抓取工具,就像蜘蛛一样,可以顺着这个网络对网页信息一个个地进行抓取。所以,我们把搜索引擎的抓取工具称之为蜘蛛。谷歌的抓取工具就叫做谷歌蜘蛛,百度的抓取工具就叫做百度蜘蛛,有些人也把蜘蛛叫做机器人,都是同一个意思。
检查网站是否可以被抓取
蜘蛛到你的网站上第一步会检测你的网站是否处于可以抓取的状态,因为不是所有的网站都愿意让搜索引擎抓取。
比如,一个网站刚刚搭建,还没有什么实质性的内容,不想立刻对外开放,也不想给搜索引擎留下不好的第一印象,于是可以选择不让蜘蛛抓取。这一步实现起来也很简单,主要是利用网站中的一个叫做robots.txt的协议文件告诉蜘蛛是否可以抓取本网站,甚至进一步规定哪些页面可以抓取,哪些页面不可以抓取。
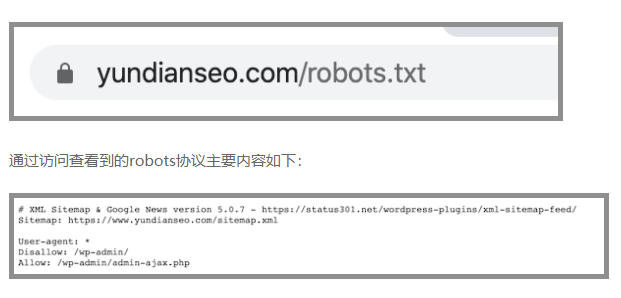
想要查看一个网站的robots文件也很简单,比如查看云点SEO网的robots文件,可以在浏览器中输入下述地址访问即可:
[info]
以上内容就告诉所有搜索引擎的蜘蛛/wp-admin/这个目录除了admin-ajax.php可以抓取,其余均不可以抓取。
另外,网站其他内容没有做规定,默认均可抓取。所以,如果robots.txt这个文件是空白的,也就默认所有内容均可抓取。
[/info]
除了robots规则,如果网页代码中包含nofollow、noindex这两个meta标签,也会禁止搜索引擎抓取、收录此网页。
抓取的路径(概念)
在获得网站内容抓取权限后,蜘蛛就会开始自己的抓取工作,搜集网站中各个网页的信息。前面提到过,蜘蛛是顺着链接爬行的,所以你的网站中的各个页面需要有链接联系起来,这样才能方便蜘蛛爬行抓取,这些链接也就是我们说的内链。
内链的一般形式有:各类导航链接、文中链接、图片链接等。如果你的某一个网页,其他页面上均无法跳转到,sitemap站点地图里也没有,外部也没有任何链接指向它,那么这个页面蜘蛛也就无法到达了,除非你单独提交给搜索引擎,但这种页面也就没什么意义了。
另外,蜘蛛的抓取工作不一定都是通过首页开始的,可能蜘蛛是顺着别的网站指向你网站中的某个页面的链接爬进来的,也就是通过外链来到了你的网站。所以,外链也能起到帮助网站被抓取的作用。

可以抓取到的内容(概念)
即便robots规则没有阻止抓取,搜索引擎的蜘蛛抓取工具也不是任何内容都可以抓取到的。和我们肉眼查看网站的方式不一样,搜索引擎看的是网站被抓取到的源代码。
任何内容都是以代码的方式呈现在搜索引擎眼中:
即便有些内容我们可以观察到,但如果不能很好地显示在代码中,那对于搜索引擎来说就是无法识别的。
在所有的网站编程语言中,Html是搜索引擎最容易识别抓取的代码,这也是为什么做SEO时要求网站必须有静态化的Html代码的原因,动态的代码程序会导致搜索引擎无法识别抓取或者抓取不完全。
[danger]当然也有不少外贸网站,首页就是一个动态的Flash动画,视觉效果确实很不错,但对于搜索引擎来说,你的首页基本上就是个空白的页面,因为搜索引擎理解不了你的Flash内容。
永远不要把一个Flash动画作为网站首页,这对于SEO非常不利。[/danger]


